DOM树(dom tree):DOM结构
当浏览器加载HTML页面时,首先就是DOM结构计算,计算出来的DOM结构就是
DOM树(把页面中的HTML标签像树状结构一样,分析出之间的层级关系)
DOM树描述了标签和标签之间的关系(节点间的关系)
我们只要知道任何一个标签,都可以依据DOM中提供的属性和方法,获取到页面中任意一个标签或者节点
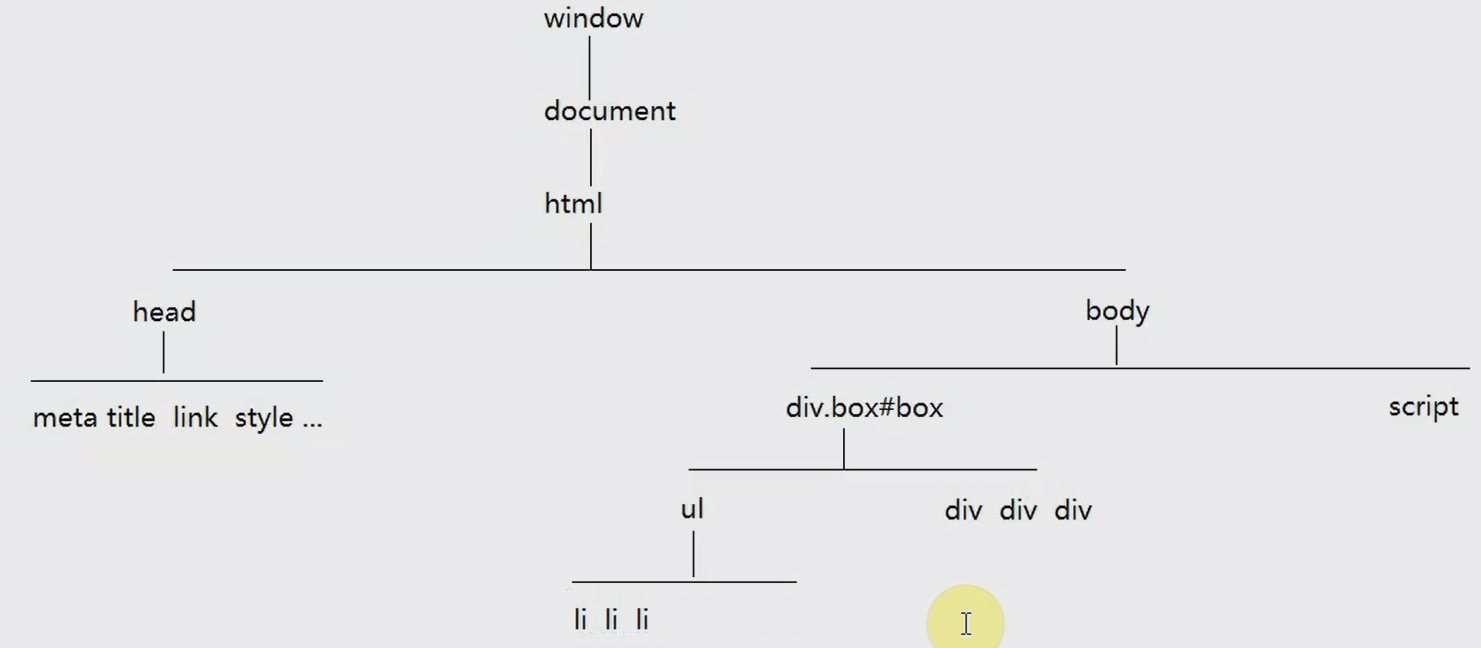
JS中获取DOM元素的方法
document.getElementById('id值')document.documentElement获取html元素对象document.body获取body元素对象document.head获取head元素对象document.getElementsByName('name属性值')[context].getElementsByTagName('标签名')[context].getElementsByClassName('class名')[context].querySelector(css的选择器:'#aaa''.ddd''.ddd div')[context].querySelectorAll(css的选择器:'#aaa''.ddd''.ddd div')
document.getElementById('id值')
在整个文档中通过元素的id属性值,获取到这个对象
getElementById是获取元素的方法
document限定了获取元素的范围,我们把这个范围称之为‘上下文【context】’
获取到的是对象数据类型的值
getElementById的上下文只能是document:
因为严格意义上,一个id是不能重复出现的,浏览器规定只能在整个文档中可以获取这个唯一id
如果页面中的ID重复了,我们基于这个方法只能获取到第一个元素,后面相同ID元素无法获取
IE6,7下 会把表单元素的name属性当做ID来使用,所以要注意id和表单元素name属性的重复问题
1 | var oBox=document.getElementById('box') |
兼容处理
在ID重复时获取所有ID为‘aaa’的标签(兼容所有浏览器):获取所有标签,判断id
在JS中,默认会把元素的ID设置为变量,不需要再进行获取设置,而且ID重复,获取的结果就是一个集合,包含所有ID元素,不重复就是一个元素对象(类似于ById的结果)
1 | function queryAllById(id){ |
获取元素集合(获取多个元素):
[context].getElementsByTagName('标签名')获取一组元素集合
在指定的上下文中,通过元素的标签名
获取一组**元素集合**(HTMLCollection)上下文是我们自己来指定的
1、获取的结果是一组元素集合(HTMLCollection,
__proto__指向HTMLCollection)(是一个类数组,不能直接使用数组的方法),2、集合中的每一个值又是一个
元素对象(对象数据类型,包含很多内置属性,例如:id、className)3、它会把当前上下文中,子子孙孙(后代)层级内的该标签都获取到(
并不是只获取到子级)4、基于这个方法
获取到的结果永远都是一个集合,不管里边是否有内容,也不管有几项;如果想操作集合中具体的某一项,需要基于索引获取到才可以
1 | var liList=oBox.getElementsByTagName('li'); |
[context].getElementsByClassName('class名')获取到一组元素集合
在指定的上下文中通过元素的样式类名(class)
获取到一组**元素集合**真实项目中,我们经常是基于样式类给元素设置样式,所以JS中经常通过样式类获取元素,
不兼容IE6~8
解决兼容问题:
获取所有标签,筛选他们的class
1 | Node.prototype.queryElementsByClassName=function(){ |
document.getElementsByName('name属性值')获取一组节点集合
上下文也只能是document在整个文档中通过元素的name属性值
获取一组**节点集合**(类数组)(__proto__指向NodeList)在IE9及以下浏览器中,只对表单元素的name属性起作用(正常来说:我们只会给表单元素设置name;给非表单元素设置name是一个不太符合规范的操作)
[context].querySelector(css的选择器:'#aaa''.ddd''.ddd div')获取的是一个元素对象哪怕选择器匹配了多个,也只获取第一个
在指定的上下文当中基于选择器(类似于css选择器)获取到指定的**
元素对象**(获取的是一个对象哪怕选择器匹配了多个,也只获取第一个)
[context].querySelectorAll(css的选择器:'#aaa''.ddd''.ddd div')获取到选择器匹配到的所有元素,结果是一个节点集合
在querySelector的基础上,我们获取到选择器
匹配到的所有元素,结果是一个节点集合(__proto__指向NodeList)(类数组)
querySelector、querySelectorAll都不兼容 IE6~8,不考虑兼容的情况下,我们能用别的方法获取尽量不要用这两个,这两个方法消耗性能较大
获取浏览器一屏幕的宽高(兼容所有浏览器)
1 | document.documentElement.clientWidth || document.body.clientWidth; |
DOM中的节点(node):元本注档1389
在html文档中出现的所有东西都是节点
元素节点:html标签;
文本节点:文字内容;
注释节点:注释内容;
文档节点:document;
每一种类型的节点都会有一些属性区分自己的特性和特征:
nodeType:节点类型;nodeName:节点名称;nodeValue:节点值;
元素节点 1
nodeType:1;nodeName:大写标签名;nodeValue:null;
1 | oBox.nodeType //1 |
文本节点 3
nodeType:3;nodeName:’#text’;nodeValue:文本内容;- 在标准浏览器中,会把
空格和换行都当做文本节点来处理
注释节点 8
nodeType:8;nodeName:’#common’;nodeValue:注释内容;
文档节点 9
nodeType:9;nodeName:’#document’;nodeValue:null;
描述节点之间关系的属性
parentNode,获取当前节点`唯一的
childNodes,获取当前元素的所有子节点
- 1、子节点:只获取到
儿子级别,不能获取到孙子级及以后 - 2、所有:
包含元素节点,文本节点等
children,获取当前元素的所有元素子节点
- 在I
E6~8中会把注释节点也当做元素节点获取到,所以兼容性不好 - 元素节点
previousSibling ,获取当前节点的上一个哥哥节点(获取的哥哥可能是元素也可能是文本等)
previousElementSibling:获取上一个哥哥 元素 节点(不兼容IE6~8)
nextSibling ,获取当前节点的下一个弟弟节点(紧跟的节点)(获取的弟弟可能是元素也可能是文本等)
nextElementSibling:获取下一个弟弟 元素 节点(不兼容IE6~8)
firstChild ,获取当前元素的第一个子节点(可能是元素也可能是文本等)
firstElmentChild:获取第一个 元素 子节点(不兼容IE6~8)
lastChild ,获取当前元素的最后一个子节点(可能是元素也可能是文本等)
lastElmentChild:获取最后一个 元素 子节点(不兼容IE6~8)
兼容处理
获取当前元素的所有元素子节点
解决
children在IE6~8中会把注释节点也当做元素节点获取到的问题
1 | function children(curEle){ |
获取当前元素的上一个哥哥元素节点
previousSibling:上一个哥哥节点
previousElementSibling:上一个哥哥元素子节点解决
previousElementSibling不兼容IE6~8的问题
1 | function prevElement(curEle){ |
DOM的增删改
document.createElement(‘标签名’)
创建一个元素标签(元素对象)
createTextNode,创建一个文本节点
[container].appendChild(创建的元素对象或已有的元素对象),把一个元素对象插入到指定容器末尾
如果文档树中已经存在了
newchild,它将从文档树中删除,然后重新插入它的新位置(如果是dom树中已有的元素对象,会把原有的删除,然后再添加到新的地方)
[container].insertBefore(创建的元素对象,要插入其前面的元素)
- 1、把一个元素对象插入到
指定容器中某一个元素标签之前 - 2、如果
未规定要插入其前面的元素,则 insertBefore 方法会在结尾插入 newnode
[curEle要克隆的元素].cloneNode(),把一个节点进行克隆
1、[curEle要克隆的元素].cloneNode():浅克隆(只克隆当前的标签,标签的样式也有,只是没有innerHTML)
2、[curEle要克隆的元素].cloneNode(true):深克隆,当前标签及里面的内容都一起克隆了
[container].removeChild(要删除的元素),在指定容器当中删除某一个元素
[curEle要操作的元素].set/get/removeAttribute(属性名,属性值)
设置、获取、删除当前元素的某一个
自定义属性;[curEle要操作的元素].setAttribute(属性名,属性值)
[curEle要操作的元素].getAttribute(属性名)
[curEle要操作的元素].removeAttribute(属性名)
1 | var oBox=document.getElementById('box'); |
上边两种方法属于独立的运作体制,不能相互混淆使用
第一种是
基于对象键值对操作方式,修改当前元素对象的堆内存空间来完成(不存在时获取到的是undefined)第二种是
直接修改页面中HTML标签的结构来完成的,此种办法设置的自定义属性可以在结构上呈现出来(不存在时获取到的是null)第一种方法设置的属性在elements控制台是
看不到的,第二种设置的能看到(myIndex看不到,myHahaha看得到)基于setAttribute设置的自定义属性值
都是字符串能用第一种不要用第二种,第二种结构上可见易被攻击,而且第二种操作的是dom耗费性能
1 | var oBox=document.getElementById('box'); |
node.attributes,获取指定节点的属性集合
用法:document.getElementsByTagName(“BUTTON”)[0].attributes;
可以使用 length 属性来确定属性的数量,能够遍历所有的属性节点并提取需要的信息
解析一个URL字符串问号传参和HASH值部分:a元素对象的hash/search两个属性分别存储了哈希值和参数值
1 | var str="http://www.baidu.com/stu?lx=1&name=AA&age=20#haha"; |